
先日ついたコメントがクソ過ぎる
このブログは驚くほど過疎っているのでコメントが付くことは稀なんですが、最近久々にコメントが付いたと思ったらまあ普通にクソカス無能ゲロゴミコメントでした。
まああまりにもクソ過ぎるのでスパム扱いして削除しても良いんですが、せっかくちゃんと答えてあげたのでブログのネタにして消化してあげようと思います。
ちなみにコメントがついた記事はこちらで、ついたコメントはこんな感じです。

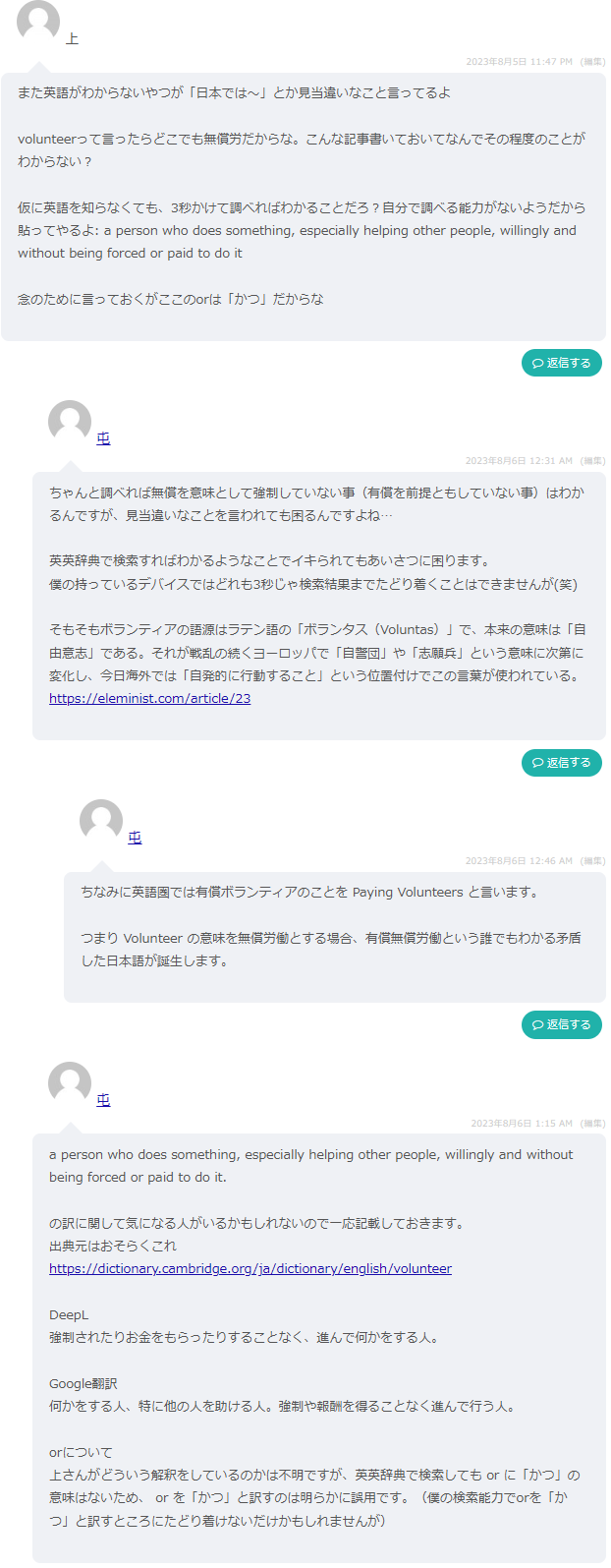
まあコメントの流れを見てもらえばいいんですが、volunteerの語釈に関して上から目線で見当違いなイチャモンを付けてるガバガバ英語自信ニキにコメント返ししている局面ですね。
しかしガバガバ英語自信ニキの検索能力も英語能力も底辺過ぎて、逆にお手本みたいな感じなのでいい教材すぎます。
そんなわけで今回は、情報の裏取りの仕方、言葉の意味の調べ方を解説していきます。
情報の裏取りの仕方
情報の裏取りは情報発信をする上で非常に重要です。
以前こんな記事を書いたんですが、僕はかなりちゃんと情報の精査を行っている方だと思うんですよね。

まあ情報を発信する以上裏取りなんかして当然なんですが…
情報の裏取りの方法としてはこんなことを意識しておけば一応OKです。
- ちゃんと調べる
- 公的機関や所在の確かな法人を情報源とする
- 前提条件や恣意的な要因がないか確認する
- 学術的に正しいか判定する(義務教育レベルでわかる範囲でOK)
- 自分の専門分野を扱う
ちゃんと調べる
バカにしてんのかと思うかもしれませんが、バカにはできない事なのでちゃんと言います。
今回付いたコメントでも偉そうに書いていますが、3秒かければ調べられるとか言ってますけど3秒でちゃんと調べられることなんかありません。
つまりちゃんと調べるができていないんですねこいつは。
その後に貼り付けている文章はググって出てきただけの英英辞書からの引用でしたが、その英文すらまともに翻訳もせずにイキり倒しています。
英語の情報の翻訳については後で詳しく書くので後回しにしますが、たとえコメントだとしても発信する前にはちゃんと調べると言った行動ができることが人としての最低限でしょう。
ちゃんと調べないことは無責任ですからね。
公的機関や所在の確かな法人を情報源とする
引用したいデータがある場合はなるべく公的機関(○○省)みたいなところから取得するのが望ましいです。
公的なデータは一応中立にデータを集められているはずなので…
続いて、非営利団体なども同じく中立である可能性が高いデータなのでこの辺を取得したいところです。
それでも欲しいデータがない場合は法人からデータを取得するしかないんですが、この時の法人は可能な限りまともな法人を選ばないといけません。
法人がまともかどうかは会社のホームページ、歴史、所在地、地図などから確認しましょう。
その辺の確認方法はこの記事でやってますね。

前提条件や恣意的な要因がないか確認する
この辺を怠る人が結構多いんですが、集計対象が偏っている場合当然偏った意見が生まれる場合があります。
例えば岸田の支持率が3%なんて画像が出回ったことがありましたが、あれは投資家を中心ネット上で回答を募集したためあれほど低い支持率になりました。(まあ僕は3%でも高すぎると思いますが)
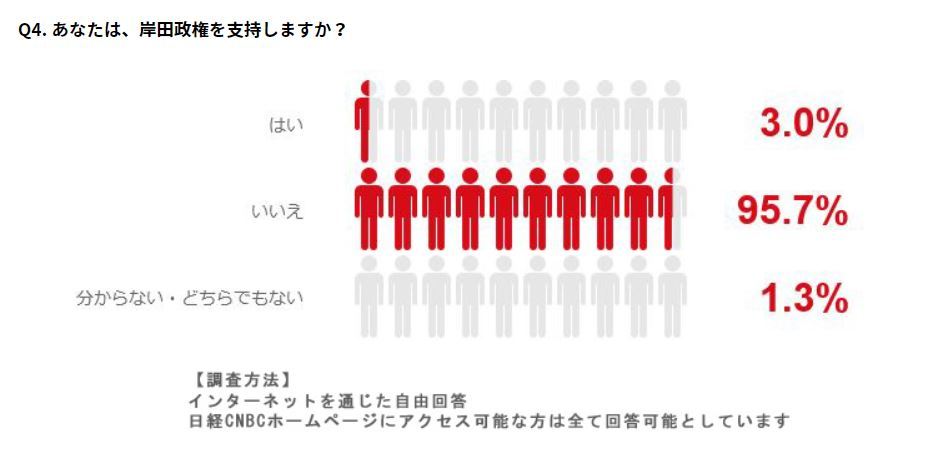
じゃあ支持率をちゃんと調べてるのはいったいどこなんだというとちゃんと調べてなんかいないんですよね…
内閣支持率は面接方式とか電話方式とか昭和感丸出しの手法でしか取得していなくて、前提条件にアポなしで訪問してきたキチガイ相手に対応してアンケートに答えるバカとか、知らない番号からの電話に平気で出てのうのうとアンケートに答えるバカとかが入ってしまうんですね。
こいつらのデータを詐欺師に売ったらかなりのヒット率になるでしょう。
まあ話が若干それましたが、統計データを見る時には前提条件がまともか?を確認して統計データとして使用することができるか?を吟味しましょう。
前提条件の他にも恣意的な要因が入る余地があって、研究費が特定の企業から出ている場合の研究などは注意が必要です。
もちろん研究なので大抵は論文とかになっているから多少はまともですが、朝食によく食べるものを生産している企業が「実は朝食は体に悪い」みたいな研究は当然しないので結果がある程度恣意的に曲げられる(結論ありきで狙った結論になる条件で研究されている)可能性があります。
対処法としては論文の引用数は適当か?とか対立する研究があるか?そもそも過去の実績がまともか?などを調べるくらいです。
まあ悪い評判のある研究はちょっと調べればぼろが出てたりするんですよね。
似たようなものでサロンや自社サービスに過度に勧誘をしていないか?もチェックすべきです。
学術的に正しいか判定する(義務教育レベルでわかる範囲でOK)
発信する以上、発信する分野に関してある程度の理解をしていないとお話にならないんですが、少なくとも自分の調べて得られる知識で正しいと判定できるのは最低限です。
と言ってもそこまで高度なことではなく、当たり前に考えて当たり前の結論だと納得できるかどうかまずは自分問いましょう。
特に数字関連の場合は数学的に正しいか?を確認するだけでもだいぶ正誤判定ができます。
例えば、いまだに税金をすべての公共事業の財源だと思っているバカが死ぬほど多くいますが、そんなことは数字で考えれば全くのでたらめだということが分かります。
まあこの辺の話は画像を引用したほうが分かりやすいのでそっちをまずは見てみましょう。
わかりやすさ重視だとこういう説明になります。
- 通貨発行権は国が持っていて、その国が発行した貨幣が市中に供給される
- 市中では通貨発行できない人たちがサービスを介して通貨を循環させる
- 循環を促すために決められたルールで税金という名目で貨幣の一部を消す
これが、通貨発行権を持つ国に対する財源にはならない税金である国税の流れの説明です。
地方税は国税とは全くの別物で、こちらは通貨発行権を持ったない地方自治体に収める財源となる税金です。(地方公共団体は市中の一部)
厳密に言うと全く意味がないとはいえ国税も財源となると言えばなるんですが、それは今回のキモである数字を使って考えましょう。(市中の財源にはならないが、通貨の所有者を移動させることができる)
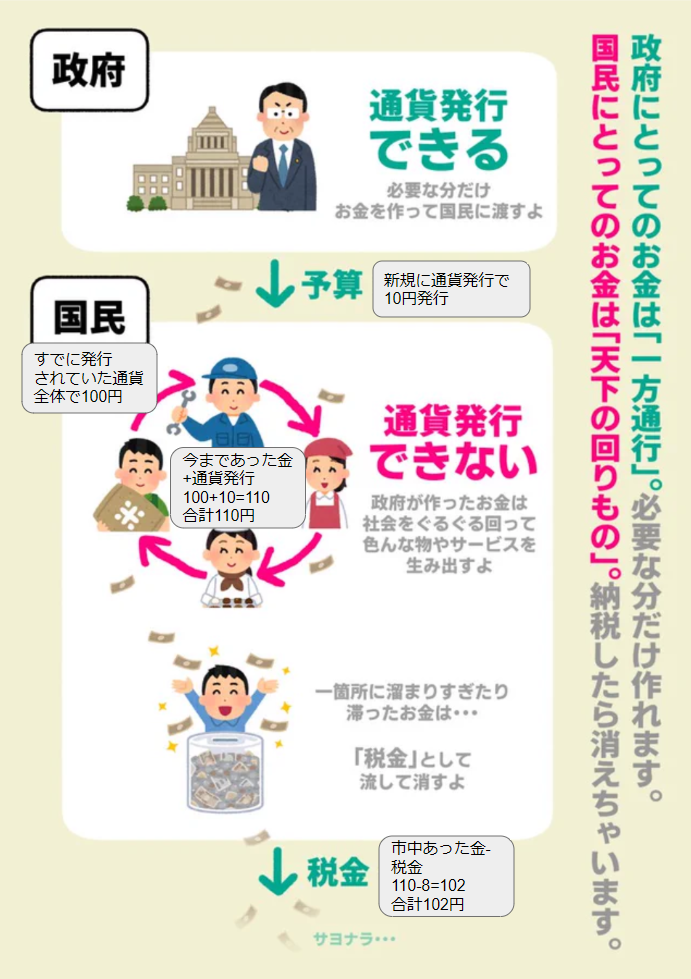
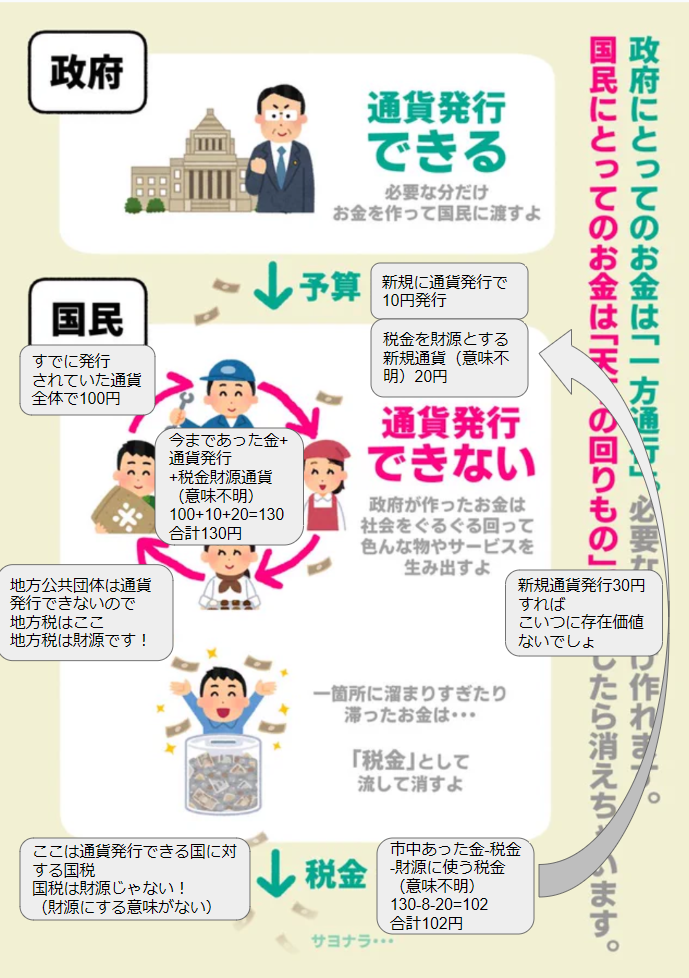
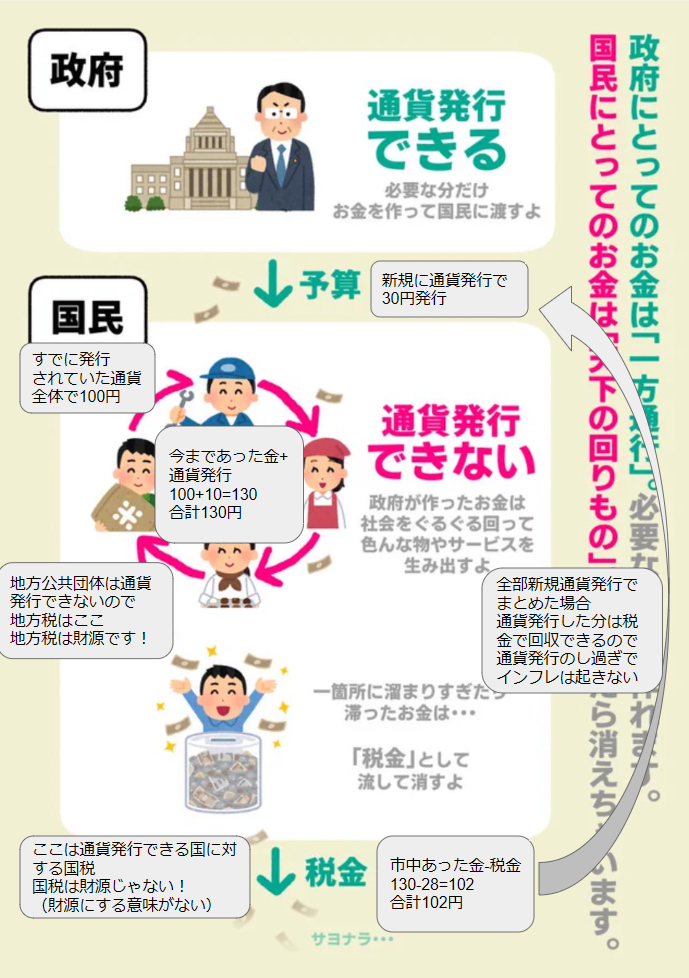
上記ツイートの画像を使用させてもらって、分かりやすい程度の桁数で数字を振ってみました。
1枚目の画像はもっとも簡潔な通貨発行→市中消費→税金徴収の流れです。
2枚目の画像は税金が財源になる世界の画像です。20円取って20円返すというキチガイムーブをかましています。(金の持ち主は変わるが、市中の金の総量は変わらない)
3枚目の画像は2枚目の画像の金の動きを通貨発行のみで書いた画像です。2枚目の画像と金の動きは全く一緒ですが、税金は1円たりとも財源になっていません。
つまり、税金を財源にするというのは同じ数字で引き算をするという意味不明な手順を踏むだけの無意味な行為です。
これは単純な引き算でしかないのでこんなのくらいは理解してほしいものです。
まあ気が向いたら税金財源論の愚かさは詳しく記事にするかもしれません。
自分の専門分野を扱う
自分が詳しいことであれば当然知識が豊富なので正誤判定も精度高くすることができます。
僕の専門分野はまあ仕事で言うとプログラマーなんですが、そっちよりは金とか確率とか4号系の方が専門分野ですね。
これらの知識は普段から収集していたり、元から得意だったりすることで自然と専門性が上がっていってるので、わけのわからないで書いている素人よりも数段上の知識を持っています。
まあ、慢心してはいけないので同じく専門知識が豊富な人や専門性を手に入れるために使用した資料などを確認したほうが良いですが。
ちなみに僕の専門性を活かした記事だとこの辺になります。


言葉の意味の調べ方
なんか思っていたよりも裏取りのところが長くなってしまった気がしますが、話を戻して言葉の意味の調べ方について解説していきます。
なんてことはない普通の話で、言葉の調べ方はこんなもんです。
- 辞書で引く
- 用例を調べる
- Wikipedia
言葉を知りたいなら辞書を引くのが正攻法です。


まあ紙の重い辞書なんて今は持っている人は少ないと思いますが、スマホのアプリでもGoogle検索でも辞書にアクセスする方法はいくらでもありますからね。
もちろん辞書によって説明方法や用例は様々なのでしっくりくる説明がされていなければ他の辞書なども確認すると良いでしょう。
辞書以外の方法だと用例を調べる方法があります。
辞書に書いてあるような用例を自分で調べてどういった意味で使われているのか知る方法ですね。
まあやることとしてはGoogle検索とかX(Twitter)での検索とかになるだけなんですが。
辞書的な固い意味だけでなく、裏の意味などが分かる場合もあるので用例も調べるのはセットにしましょう。(辞書によっては固くない裏の意味をうまく載せているのもあるが)
手っ取り早く知るならWikipediaも便利です。
ある程度の信頼度で見ればさっくり意味を理解するくらいの役には立ちます。
少なくともボランティア活動で運営されているとは言え、基本的にはかなりまともな人達が書いてますからね。
少なくともこんな過疎ブロガーよりは信用があると言って良いでしょう。(Wikipediaを盲目的に信頼していいとは言わないが)
英語の情報源の使い方
英語が非常に堪能な人は別に英語の情報を英語のまま処理するのが一番なのでそれでいいんですが、そうでないのであれば必ず機械翻訳を使った方が良いです。
バカほど自分の英語の能力を過信して機械翻訳をバカにしますが、少なくともバカの英語力よりは精度が高い翻訳ができます。
英語情報の読み方としては、こんな感じがベストです。
- 日本語翻訳をかける(複数が好ましい)
- 翻訳のおかしな点を原文と翻訳を見ながら修正する
- 翻訳がおかしな点に含まれる怪しい語句・知らない語句はその都度英英辞書を引く

日本人は文法は一通り学校教育で習っていますし、知っている単語と翻訳のひな型さえあれば大抵の英文は読めます。
英語はパズルみたいなもんで知っている文の形であれば後は単語の意味を知っているかですからね。
単語の意味は調べればわかるし、文法なども機械翻訳でいい感じに示してくれます。
もちろん、機械翻訳は一般的に正答率が高いようなものを出力してくるので間違っていることもあり、鵜呑みにせず最後は自分で翻訳する必要があります。
専門用語だったり、元の文章が口語体で文法的におかしかったりなど様々な理由はありますが、精度が低い部分は人間が上手く修正しましょう。
バカはAIが何でもできると思っていたりして、できないことがあると全部を否定しようとしがちですが、何事も0か100だけじゃないんです。
AIが90できるんなら90やってもらって人間が10の仕事を補完してやりましょう。
で、人間が補完するときに知らない単語がある時の調べ方としてはこんな感じです。
たとえば今回だとvolunteerの話ですが、volunteerを英英辞書で引きます。
英英辞書は英単語を英語で解説している辞書のことで、日本で言う国語辞書ですね。
英英辞書を使うメリットとしては無理やり日本語に当てはめるなんてことをしていないで、その単語本来の意味を解説していることです。
そして引いた際に出てくる英文の語釈を翻訳してここで初めて日本語として処理します。
まあ早さ重視の時とか一番有名な意味を早く知りたい時とかは英和辞書でもいいですけどね。
最後のまとめ
今回は「【責任もって】裏取りと言葉の意味と誤用しないために」というタイトルで情報の裏取りの仕方、言葉の使い方と意味の調べ方を解説しました。
事の発端は以前書いた記事についたコメントだったんですが、あまりにもお粗末すぎるクソコメントなので、情報収集の大切さや語句を正しく使うための調べ方を解説しています。
情報の裏取りとして自分が大事にしていることは以下の通りです。
- ちゃんと調べる
- 公的機関や所在の確かな法人を情報源とする
- 前提条件や恣意的な要因がないか確認する
- 学術的に正しいか判定する(義務教育レベルでわかる範囲でOK)
- 自分の専門分野を扱う
可能な限り公平で信頼度の高い情報源から恣意的な操作などがされていないか?を確認しつつ情報を取得し、取得した情報が一般的な論理や法則から逸脱していないか?を検討しましょう。
また自分から情報発信する場合は、基本的には自分の専門分野など他人よりも詳しいことをテーマとして選ぶことも重要です。
続いては言葉の調べ方ですが、言葉を知りたいのであればまずは何はともあれ辞書です。
辞書にはその言葉の解説と用例が載っています。
しかし、辞書には当然スペースの制限があるので、意味は説明されても実際にどう使われているのかはわからないなど理解が不十分になってしまうものもあります。
なので、実際に使われている用例をX(Twitter)などで探してみると良いでしょう。
サクッと知りたいだけならWikipediaもかなり便利なので参考程度に活用しましょう。
最後に英語の情報源に関してですが、変なプライドは捨てて機械翻訳しましょう。
そして翻訳を見つつ原文を自分でも読むことで翻訳のおかしな部分を自分で修正するのが一番楽で早くて正確です。
その際わからない単語などが出現した場合は英英辞書を使ってその語句本来の意味を調べましょう。
これくらいのことを意識しておけば少なくとも最低限の裏取りと言葉の使い方はできるようになっていると思います。
間違ってもorを真逆の意味の「かつ」と訳してしまうようなことはないでしょう。
こんな記事も書いています。



コメント